데이터 엔지니어를 조사하게 된 이유
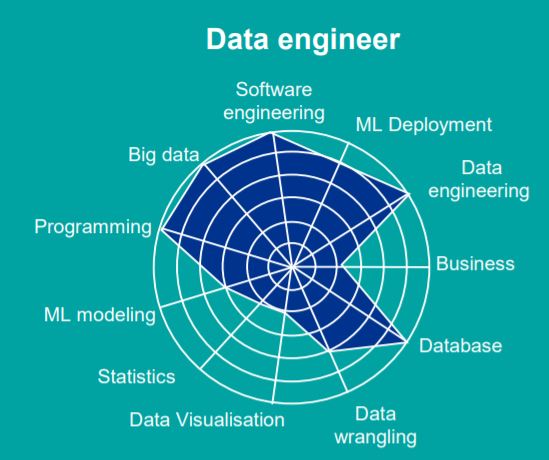
데이터 엔지니어가 되고싶어졌다. 흔한 계기로 시작했지만 나에겐 매우 중요한 일이다. 데이터 엔지니어가 되고 싶다는 이야기를 할 때마다 "데이터 엔지니어가 왜 되고싶어?"라는 질문이 항상 뒤따랐다. 나는 데이터 엔지니어를 정의하지 못하기 때문에 항상 추상적인 대답을 해야했다. 물론 이제 시작하는 입장에서 추상적인 대답이 틀린 것은 아니라고 생각한다. 하지만 되고싶다면 적어도 무슨 일을 하는지, 어떤 능력이 필요한지는 알고 목표 의식을 가져야한다. 학생 때처럼 뉴스에서 본 아동성추행범 잡아쳐넣겠다고 막연하게 검사가 되겠다고 이야기 하기에는 현실성 있게 커버렸다.
먼저 데이터 엔지니어를 정의하고 있는 기업들의 글들을 정리해보기로 했다. 데이터 엔지니어는 직업이고, 그들은 회사에 다닌다는 명료한 이유로 기업에서 설명하는 데이터 엔지니어를 먼저 조사해보기로 했다. 모든 내용들을 조사할 수 없어 명확한 정의가 되지 못할 수 있지만, 흔히 말하는 대기업들의 기술블로그들을 통합해보면서 정답을 찾아가는 첫걸음을 시작하려한다.
기업 블로그로 보는 데이터 엔지니어
나는 데이터 엔지니어에 대해 알아보기 위해 여러 기업들이 채용하는 데이터 엔지니어 포지션의 JD들과, 해당 기업에서 데이터 엔지니어가 어떤 일을 하는지 설명하는 기술 블로그 글들을 읽어보기로 했다.
Job Description
아래는 현재(2021.06.23) 조회(검색)할 수 있는 몇개의 데이터 엔지니어 JD들이다.
- 네이버
[Search] Data Science 데이터 분석 & 엔지니어 - 카카오
데이터 엔지니어 및 사이언티스트 (경력) - 라인
Growth Hacking Data Engineer - 쿠팡
Senior, Data Engineer(GFS, Global FInance System) - 배달의민족
데이터 엔지니어 모집(3년 이상) - 당근마켓
데이터 플랫폼 백엔드 개발 (신입/경력) - 토스
Data Engineer(토스코어) - 쏘카
데이터 엔지니어 - 카카오
빅데이터 플랫폼 개발자 모집
기업/부서마다 필요한 역량이 다를 수 있다. 그럼에도 다양한 JD들의 공통점이 보인다면, 그것은 데이터 엔지니어의 기본 소양이 될 수 있다. 혹시나 선택된 단어들의 공통점이 있는지 해당 JD들의 raw text를 이용하여 word cloud를 만들어봤다.

가장 크게 보이는 단어들은 "데이터, 개발, 경험이, 있으신, 위한, 파이프라인" 정도 되보인다. 정제되지 않는 input의 결과에서 굳이 의미를 뽑아보자면, "데이터 엔지니어 역시 개발 경험이 중요하다" 정도 될 수 있겠다.
기술 블로그
다음으로 데이터 엔지니어의 역할에 대해 기술한 블로그들도 읽어보았다.
- 카카오
데이터 엔지니어링이란 - 쏘카
데이터 엔지니어링 팀이 하는 일 - 토스
토스팀에 데이터가 흐르게 하는 데이터 플랫폼 팀을 만나다 - 배달의민족
2021 우아한 형제들 경력 개발자 인터뷰 (강선구)
이 글 역시 각 기업에서 어떤 일을 하는지에 대해 기술하기 때문에, 서비스에 따라 세부적인 내용은 상이할 수 있다. 역시 혹시나 하는 마음으로 raw data들로 word cloud를 만들어보았다.

의미있는 결과를 갖기엔 너무 input을 복붙했다. 그와중에 데이터는 항상 중심에 자리를 잡고 있는 것이 신기하다.
내가 생각하는 데이터 엔지니어의 역량
위 글들을 쭉 읽으면서 느꼈던 데이터 엔지니어의 역량과 그렇게 생각하게 된 키워드/문구를 간단하게 정리해봤다. 참고로 데이터 엔지니어링 업무가 아직 정형화되지 않아서 기업마다 운영 방식이 다르다고 하며, 데이터 엔지니어가 하는 일은 "데이터에 관련된 모든 것"이라고 정의하는 문구가 이해가 되었다.
전체 시스템을 이해해야한다.
- hadoop ecosystem
- 데이터 파이프라인 시스템 설계/구축/관리
- 리눅스 환경
- shell programming (시스템 자동화에 사용될듯?)
- 고성능, 고가용성, 확장성을 갖춘 클라우드 분산 시스템 구축 경험
- 대용량 / 실시간 처리 / 확장성을 고려한 클라우드(AWS,GCP) 기반 데이터 파이프라인 구현/개선
- 관련 플랫폼 경험이 필요하다.
- spark
- hive
- hadoop
- presto
- airflow / kubernetes (비교 필요)
- kafka
- zeppelin
- jupyterHub
- Redash
- Flink
- BigQuery
- Impala
- 데이터를 이해해야한다.
- 어떤 데이터인지 인지해야한다.
- data visualization
- dash board
- 로그(정형/비정형) 데이터 전처리
- Tableau(태블로)
- 구글 스프레드 시트
- 구글 데이터 스튜디오 (구글 플랫폼에 적합 / BigQuery)
- A/B 테스트
- GA(Google Analytics) - 데이터가 어떻게 소비될지 이해해야한다.
- feature engineering (데이터 분석가와 밀접 관련)
- 로그 ETL, 데이터 가공 + 데이터 분석, feature 발굴 (데이터 가공 뿐만 아니라 feature 발굴?)
- 데이터 분석/활용 경험
- 데이터 분석을 통한 비즈니스 지표 및 통찰력
- 데이터 디스커버리 서비스 개발
- MLOps - 데이터의 저장/조회 과정도 이해해야한다.
- SQL
- HiveQL
- 하나 이상의 Database 사용 경험
- MySQL / SparkSQL
- 어떤 데이터인지 인지해야한다.
- 개발 능력이 중요하다.
- 개발에 대한 지식/경험이 필요하다.
- 개발 경력
- 언어 능통(python, scala, java, c++, Kitlin, swift )
- Server/Client 개발 등 IT 서비스 개발/운영 경험 3년 이상
- Git 능통자
- 개발 ecosystem에 능숙하신 분 (java+springboot)
- 확장 가능한, 서비스 지향적, 신뢰할 수 있는 아키텍처 구성
- 분산 환경(특히 백엔드 데이터 프로세싱)에서 대규모 데이터 다룬 경험
- Restful API / gRPC
- MSA
- 유지보수 (클린코드/아키텍처/CI/CD)
- DDD (Domain Driven Development)
- 처리 속도(로직 최적화/캐싱)
- HTTP 통신 : Flask / FastAPI
- RPC 통신 : gRPC
- CI/CD 파이프라인 툴 : BuddyWorks (유료)
- 배포 툴 : ArgoCD (Git-ops) - 대용량 처리에 대한 이해가 필요하다.
- 대용량 분산 처리 경험
- 대용량 트래픽 서비스 개발/운영 ("대용량 트래픽 = 빅데이터"은 아니지만 연관성이 있겠다)
- Single point of failure (단일 장애점: 전체 시스템에서 고장이 발생하면 전체 시스템의 작동이 멈춰버리는 현상) - 서비스를 이해해야한다.
- 서비스를 이해하고 성장시키고 싶으신 분 - 문제해결 능력이 중요하다.
- 최신 논문의 빠른 이해를 통해 직면한 문제 해결
- 금융 시스템 설계/구축 및 문제해결
- 복잡한 기술적, 사업적 문제 해결
- 개발에 대한 지식/경험이 필요하다.
데이터가 사용자 -> 서버 -> 사용자가 되는 흐름에서 관련된 모든 일에 관여하기 때문에, 데이터 엔지니어의 역할 범위가 매우 넓고 알아야 할 내용이 많다. 현재 생각하는대로 분야를 나누어서 이야기하면 다음과 같이 나타낼 수 있을 것이다.
- 사용자 -> 서버
- Front-end
사용자의 어떤 데이터가, 어떻게 수집되어야 하는지 알아야한다. - Back-end
수집된 데이터가 어떻게 저장되어야하는지, 어떤 처리를 해야하는지 알아야한다. - Data
수집 데이터를 어떻게 관리할지 알아야한다.
- Front-end
- 서버 -> 사용자
- Data
어떤 data를 필요로 하는지, 어떻게 효율적으로 제공할 수 있는지 알아야한다. - Back-end
Data를 어떻게 활용할지, 어떤 처리를 해야할지 알아야한다. - Front-end
Data 활용 결과가 어떻게 적용될지, 어떻게 보여줘야할지 알아야한다.
- Data
여기에 내가 느낀 중요한 사실이 2가지 더 있다.
첫 번째로는 데이터 중심 애플리케이션 개발이다. 내가 학부 때 배웠던 시스템에서 많은 변화가 있었다고 느낀다. 확실히 시스템 전체가 데이터를 중심으로 설계되어있다. 이러한 변화를 손놓고 있던 내가 인지하지 못했거나, 학부 때 공부를 게을리했던 것 같다.
두 번째로는 협업 능력이다. 데이터가 중심에 있기 때문에, 사용자에게 제공되는 서비스는 물론이고 사내 시스템, 데이터 분석 등 많은 접점을 가지고 있다. 이로 인해 다른 이들과의 협업이 중요한 능력으로 꼽힐 수 있다. 이전에 "OKKYCON 2021 : 협업의 기술"에서 들었던 기억에 남는 문구가 있다.
인간은 대화를 통해서 상대방을 전부 이해할 수 없다.
그럼에도 불구하고 노력해야만 한다.
회사에서 커뮤니케이션에 문제가 있을 때 상대방을 원망했던 적이 있다. 내가 그 분을 이해할 수 없는 건 당연한 일이였을지 모른다. 내가 해야 할 일은 그럼에도 더 원활한 커뮤니케이션을 만들 수 있게 노력하는 것이었다. 물론 커뮤니케이션을 거절한 사람은 아직도 용서가 안된다.
데이터 엔지니어링은 서비스의 데이터 유통업
기업들이 데이터 엔지니어를 설명하는 글들을 보면서 유통업이 생각이 났다. 머리가 안좋아서 그런지 한마디로 정의하는 걸 좋아한다. 유통업은 소비자와 생산자 사이에 물품을 배달하고, 효율적인 배달 체계를 고민하고, 어떤 물건인지에 따라 배송 방법도 달라질 수 있다. 유통업에 대해서 전혀 모르지만... 물건이 상대방에게 어떻게 출발하고 도착하는지 전체 시스템을 이해해야하는 모습이 닮아있다고 생각한다.
데이터 엔지니어링이 무엇인지 고민해보면서 정리된 것이 많다. 목표의식도 확실해지고, 어렵지만 재밌을 것 같다는 생각이 들었다. 특히 데이터 중심으로 서비스들이 바뀌고 있는 걸 모르고 있었다는게 부끄러우면서도 알게되어 다행이라 생각한다. 먼 미래에는 자부할 수 있는 데이터 엔지니어가 될 수 있길 기대해본다!
'고민하기' 카테고리의 다른 글
| [번역 - Cornell Univ.] 분할 상환 분석 (Amortized Analysis) (0) | 2021.07.09 |
|---|---|
| 빅오(O)는 왜 최악의 경우가 아닐까 (0) | 2021.07.02 |
| 구글 파이썬 스타일 가이드 - 2.12 Default Argument Values (Mutable vs Immutable) (0) | 2021.06.29 |
| 객체(Object), 클래스(Class), 인스턴스(Instance)를 구분할 수 있을까 (0) | 2021.06.29 |
| Parameter(매개변수)와 Argument(전달인자)의 차이 (0) | 2021.06.27 |